AI Agent 跑不穩,多半不是模型不夠聰明,而是你把它當成一次 function call 在用。把 LLM 當作確定性 API 串進業務流程,是過去一年多最常見、也最痛的踩坑。模型本身會持續進步,但「不確定性」是它的設計特性,不是 bug;繞不開這點,再強的模型接進來都會出事。
近期社群的討論明顯在轉向:與其追逐參數更大的模型,不如把 agent 當成分散式系統來設計。LangGraph、AutoGen、Pydantic AI,以及各家自研的 orchestrator,本質上都在解同一件事——當每一步輸出都是機率分佈時,如何讓整體流程仍然可預測、可重試、可觀測。
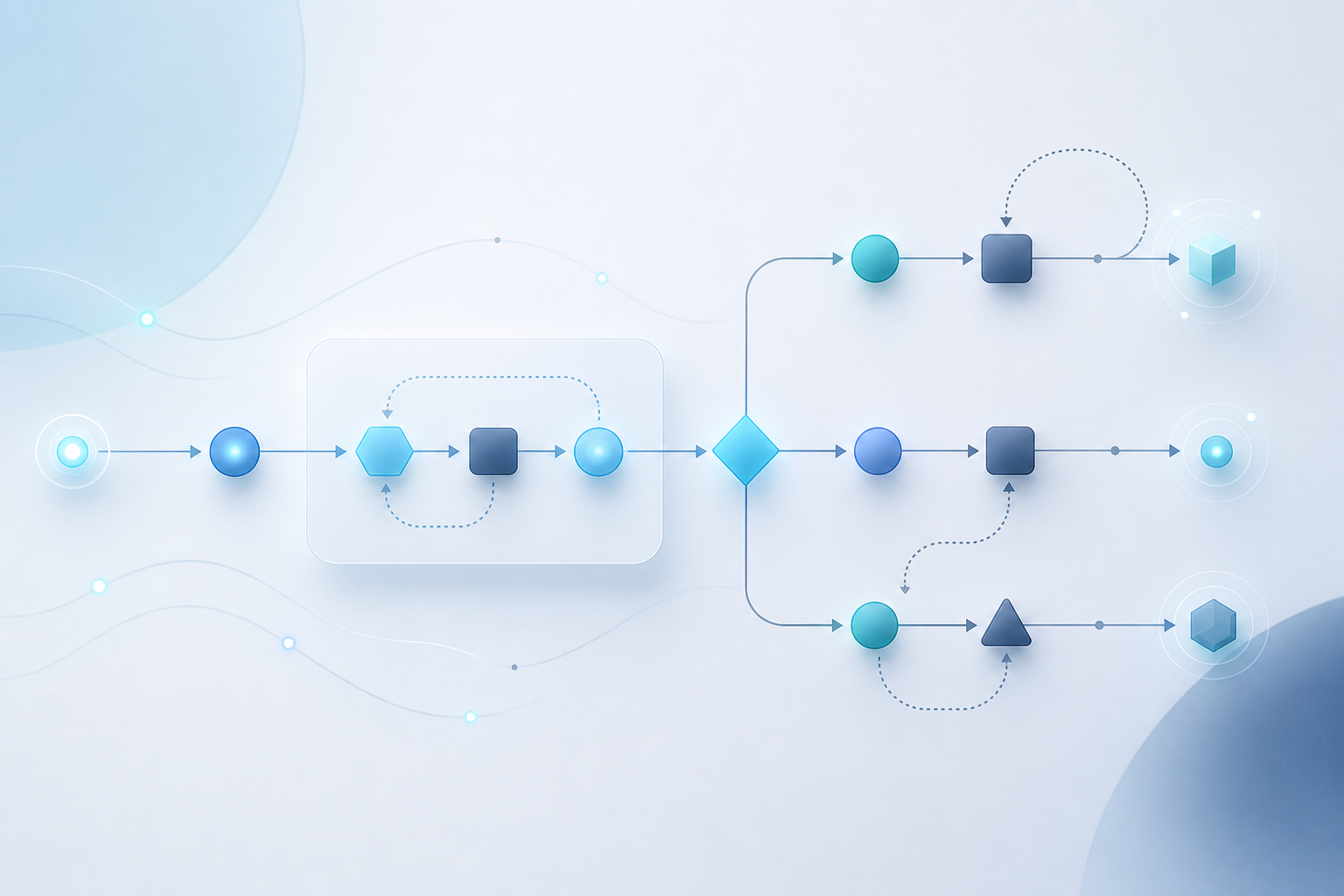
Agent 不是 RPC,是一個小型分散式系統
寫過微服務的人應該很熟悉這幾件事:網路會斷、下游會慢、回傳格式偶爾會壞。LLM 比這些更糟,因為它連「同樣的輸入回同樣的輸出」都不保證。
舉個例子,假設你要做一個客服自動回覆 agent,需要查訂單、判斷退款政策、再寫回覆。最天真的寫法是把三步揉成一個大 prompt,希望模型一次搞定。實務上,這種設計 demo 很漂亮,上線後會看到各種詭異行為:模型自己幻想訂單編號、忘記呼叫工具、或同樣的 query 重試兩次得到兩種答案。
把它當成 workflow 來看就清楚多了:
# 示意:實際工具呼叫與 schema 請對應你選的 framework
def handle_ticket(ticket):
order = call_tool("get_order", ticket.order_id)
policy = call_tool("check_policy", order)
draft = llm.write_reply(order, policy)
return validate_or_retry(draft)
每一步都要有明確的輸入輸出 schema、有 timeout、能單獨重跑、把中間狀態存起來。這些都是傳統後端工程做過幾十年的事,只是換到 LLM 場景重新做一遍。
工程化才是真議題
模型層的競爭已經進入邊際遞減。主流商用模型在多數企業任務上的差距,對最終產品體驗來說不再是決定性因素。真正會拉開差距的,是這些工程細節:
- 可觀測性:每次 agent 跑了哪些步驟、用了什麼 prompt、花了多少 token,要能像 APM 那樣回放。
- 評估流程:不是寫完跑兩個 case 就上線,而是要有測試集、有 regression、有人工標註的迴圈。
- 成本分層:不同步驟用不同模型,便宜模型做分類與抽取、貴模型做生成,是基本功不是優化。
- 降級策略:模型 API 掛掉時,至少要能 fallback 到規則或人工介入,不能整條服務跟著倒。
這些東西聽起來不性感,沒有「我們接了最新模型」那麼好行銷,但它們才是讓 AI 功能真正能放進生產環境的關鍵。
我們的觀察
我們在報價時通常會這樣提醒客戶:把 AI 當成一個會犯錯的初級員工,而不是一台精準的計算機。願意花在 prompt 上的力氣,後面至少要再花一倍在錯誤處理、log 與評估流程上。台灣中小企業導入 AI 最常掉的坑,不是選錯模型,而是低估了周邊工程的份量——這部分省下來的時間,後續通常會用幾倍奉還。